
这是一个创建于 2955 天前的主题,其中的信息可能已经有所发展或是发生改变。
本文以 Andrew Ng 的《 Advice for applying Machine Learning 》为基础进行拓展。
克隆 Notebook
本文以 Bremen 大学机器学习课程的教程为基础的。总结了使用机器学习解决新问题的一些建议。包括:
可视化数据的方法
选择一个适合当前问题的机器学习方法
鉴别和解决过拟合和欠拟合问题
处理大数据库问题(注意:不是非常小的)
不同损失函数的利弊
本文以 Andrew Ng 的《 Advice for applying Machine Learning 》为基础。
这个笔记的目的是用一个互动的方法解释这些观点。有些建议是可以讨论的。它们仅是建议,不是严格的规则。
翻译参考来自 http://blog.jobbole.com/85680/
数据集
我们使用 sklearn 的 make_classification 函数来生成一些简单的玩具数据:
注意到我们为二分类生成了一个数据集,这个数据集包括 1000 个数据点,每个特征 20 维。我们已经使用 pandas 的 DataFrame 类把数据和类别封装到一个共同的数据结构中。我们来看一看前 5 个数据点:
通过直接查看原始特征值,我们很难获得该问题的任何线索,即使在这个低维的例子中。因此,有很多的提供数据的更容易视图的方法;其中的小部分将在接下来的部分中讨论。
可视化
当你接到一个新的问题,第一步几乎都是可视化,也就是说,观察你的数据。
Seaborn 是一个不错的统计数据可视化包。我们使用它的一些函数来探索数据。
第一步是使用 pairplot 生成散点图和直方图。两种颜色对应了两个类别,我们使用了特征的一个子集、仅仅使用前 50 个数据点来简化问题。
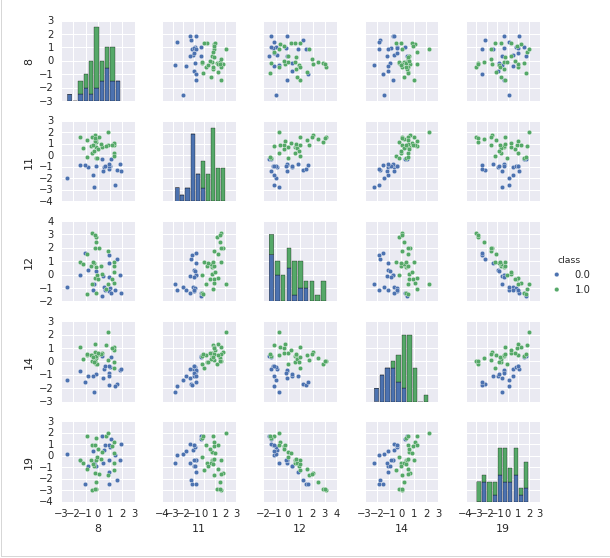
基于该直方图,我们可以看到一些特征比其他特征对分类更有用。特别地,特征 11 和 14 看起来有丰富的信息量。这两个特征的散点图显示类别在二维空间中几乎是线性可分的。要更加注意的是,特征 12 和 19 是高度负相关的。我们可以通过使用 corrplot 更系统地探索相关性:
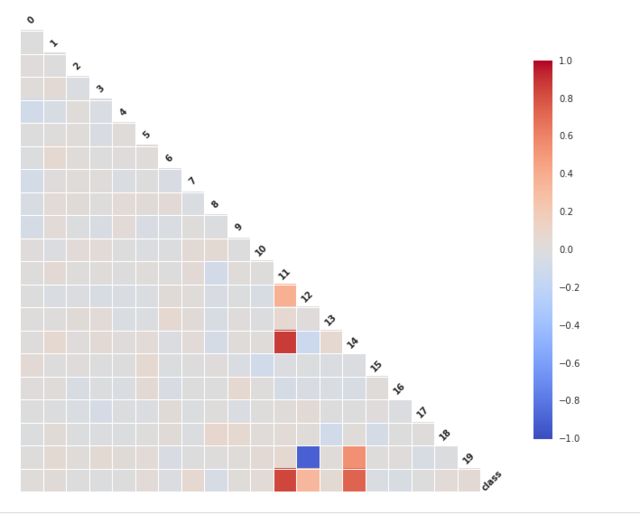
我们可以发现之前的观察结果在这里得到了确认:特征 11 和 14 与类强相关(他们有丰富的信息量)。更进一步,特征 12 和特征 19 强负相关,特征 19 和特征 14 强相关。因此,有一些特征是冗余的。这对于有些分类器可能会出现问题,比如,朴素贝叶斯,它假设所有的特征都是独立的。剩下的特征大部分都是噪声,他们既不相互关联,也不和类别相关。
注意到如果特征维数较大、数据点较少的时候,数据可视化会变得更有挑战性。
方法的选择
一旦我们已经使用可视化方法对数据进行了探索,我们就可以开始应用机器学习了。机器学习方法数量众多,通常很难决定先尝试哪种方法。这个简单的备忘单(归功于 Andreas Müller 和 sklearn 团队)可以帮助你为你的问题选择一个合适的机器学习方法(供选择的备忘录见 http://dlib.net/ml_guide.svg )
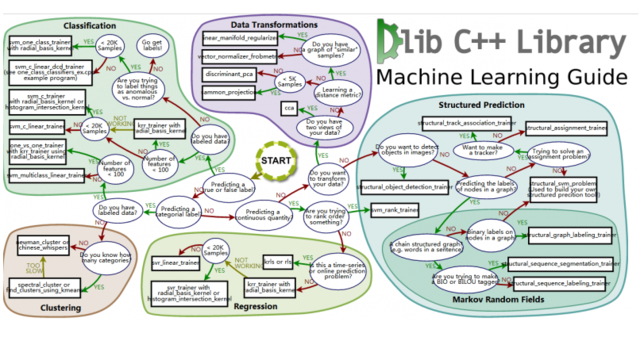
我们有了 1000 个样本,要预测一个类别,并且有了标签,那么备忘单推荐我们首先使用 LinearSVC ( LinearSVC 代表线性核的支持向量分类,并且对于这类特殊问题使用一个有效的算法)。所有我们做了个试验。 LinearSVC 需要选择正则化;我们使用标准 L2 范数惩罚和 C=10.我们分别画出训练分数和验证分数的学习曲线(这个例子中分数代表准确率):
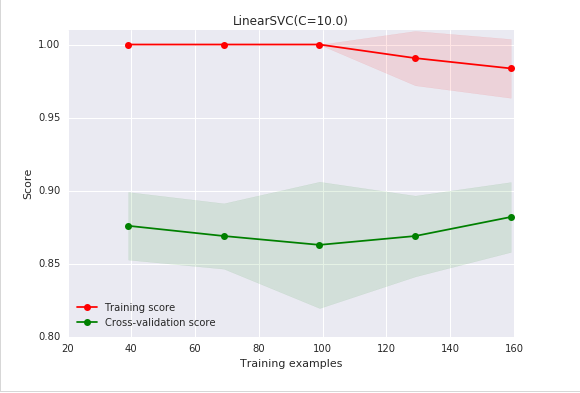
我们可以注意到训练数据和交叉验证数据的错误率有很大的差距。这意味什么?我们可能过度拟合训练数据了!
解决过拟合
有很多方法来减少过拟合:
增加训练样本数
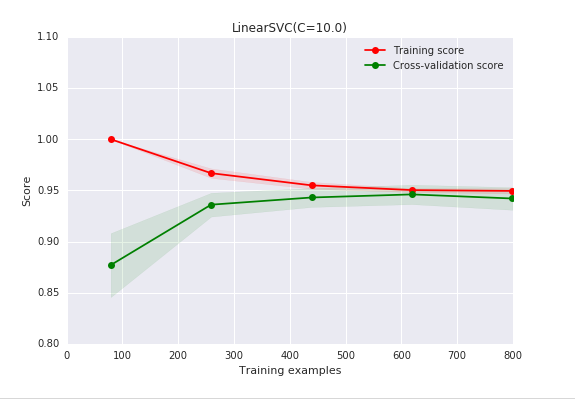
可以看到当训练数据增加时,验证分数越来越大,差距越来越小;因此现在不再过拟合了。有很多获得更多数据的方法,比如( a )可以尽力投资收集更多数据,( b )基于现有数据创造一些人为的数据(比如图像旋转,平移,扭曲),或者( c )加入人工噪声。如果以上的这些方法都不可行,就不可能获得更多的数据,我们或者可以
减少特征的维数 (从我们可视化中可以知道,特征 11 和 14 是信息量最大的)
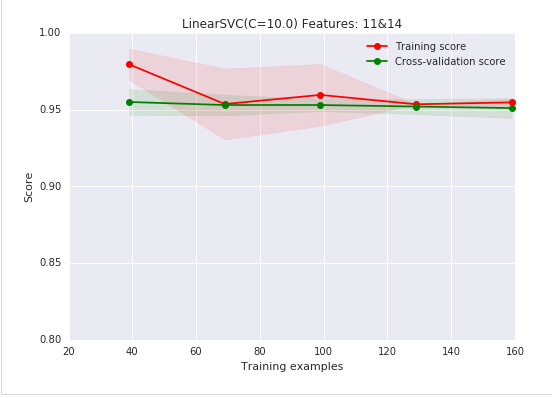
注意到,因为我们是手动的挑选特征,而且在比我们给分类器更多的数据上,这有一点作弊的意味。我们可以使用自动挑选特征:
因为雪球篇幅字数有限,所以就先转载到这儿了,余下内容请移步 https://uqer.io/community/share/58117520228e5b1627bc555d ,作者:量化投资与机器学习
克隆 Notebook
本文以 Bremen 大学机器学习课程的教程为基础的。总结了使用机器学习解决新问题的一些建议。包括:
可视化数据的方法
选择一个适合当前问题的机器学习方法
鉴别和解决过拟合和欠拟合问题
处理大数据库问题(注意:不是非常小的)
不同损失函数的利弊
本文以 Andrew Ng 的《 Advice for applying Machine Learning 》为基础。
这个笔记的目的是用一个互动的方法解释这些观点。有些建议是可以讨论的。它们仅是建议,不是严格的规则。
翻译参考来自 http://blog.jobbole.com/85680/
数据集
我们使用 sklearn 的 make_classification 函数来生成一些简单的玩具数据:

注意到我们为二分类生成了一个数据集,这个数据集包括 1000 个数据点,每个特征 20 维。我们已经使用 pandas 的 DataFrame 类把数据和类别封装到一个共同的数据结构中。我们来看一看前 5 个数据点:

通过直接查看原始特征值,我们很难获得该问题的任何线索,即使在这个低维的例子中。因此,有很多的提供数据的更容易视图的方法;其中的小部分将在接下来的部分中讨论。
可视化
当你接到一个新的问题,第一步几乎都是可视化,也就是说,观察你的数据。
Seaborn 是一个不错的统计数据可视化包。我们使用它的一些函数来探索数据。
第一步是使用 pairplot 生成散点图和直方图。两种颜色对应了两个类别,我们使用了特征的一个子集、仅仅使用前 50 个数据点来简化问题。

基于该直方图,我们可以看到一些特征比其他特征对分类更有用。特别地,特征 11 和 14 看起来有丰富的信息量。这两个特征的散点图显示类别在二维空间中几乎是线性可分的。要更加注意的是,特征 12 和 19 是高度负相关的。我们可以通过使用 corrplot 更系统地探索相关性:

我们可以发现之前的观察结果在这里得到了确认:特征 11 和 14 与类强相关(他们有丰富的信息量)。更进一步,特征 12 和特征 19 强负相关,特征 19 和特征 14 强相关。因此,有一些特征是冗余的。这对于有些分类器可能会出现问题,比如,朴素贝叶斯,它假设所有的特征都是独立的。剩下的特征大部分都是噪声,他们既不相互关联,也不和类别相关。
注意到如果特征维数较大、数据点较少的时候,数据可视化会变得更有挑战性。
方法的选择
一旦我们已经使用可视化方法对数据进行了探索,我们就可以开始应用机器学习了。机器学习方法数量众多,通常很难决定先尝试哪种方法。这个简单的备忘单(归功于 Andreas Müller 和 sklearn 团队)可以帮助你为你的问题选择一个合适的机器学习方法(供选择的备忘录见 http://dlib.net/ml_guide.svg )

我们有了 1000 个样本,要预测一个类别,并且有了标签,那么备忘单推荐我们首先使用 LinearSVC ( LinearSVC 代表线性核的支持向量分类,并且对于这类特殊问题使用一个有效的算法)。所有我们做了个试验。 LinearSVC 需要选择正则化;我们使用标准 L2 范数惩罚和 C=10.我们分别画出训练分数和验证分数的学习曲线(这个例子中分数代表准确率):

我们可以注意到训练数据和交叉验证数据的错误率有很大的差距。这意味什么?我们可能过度拟合训练数据了!
解决过拟合
有很多方法来减少过拟合:
增加训练样本数

可以看到当训练数据增加时,验证分数越来越大,差距越来越小;因此现在不再过拟合了。有很多获得更多数据的方法,比如( a )可以尽力投资收集更多数据,( b )基于现有数据创造一些人为的数据(比如图像旋转,平移,扭曲),或者( c )加入人工噪声。如果以上的这些方法都不可行,就不可能获得更多的数据,我们或者可以
减少特征的维数 (从我们可视化中可以知道,特征 11 和 14 是信息量最大的)

注意到,因为我们是手动的挑选特征,而且在比我们给分类器更多的数据上,这有一点作弊的意味。我们可以使用自动挑选特征:
因为雪球篇幅字数有限,所以就先转载到这儿了,余下内容请移步 https://uqer.io/community/share/58117520228e5b1627bc555d ,作者:量化投资与机器学习
 |
1
sj815 2016-11-01 14:48:58 +08:00 楼主考虑新工作嘛?机器学习
|
 |
2
practicer 2016-11-02 14:30:03 +08:00
谢谢分享, 如果数据量大, 如何效率的调参数, 如何效率的调整特征呢? 由于每次训练会耗时过久, 有应付的方法吗?
|
 |
3
qfdk 2016-11-02 15:57:58 +08:00 via iPhone
谢谢分享 为啥不用 Scala 呢 看着满满的 py .
|
|
4
qfdk 2016-11-02 16:00:16 +08:00 via iPhone
要是赢 py 似乎有个 pyldavis 要是 可视化 感觉还是 zeppelin 好玩点儿 毕竟是 df 嘛
|
 |
5
JohnSmith 2016-11-03 10:19:40 +08:00
如果依照 V2EX 的约定的话,转载只要转链接就 ok 了
|


 |
8
songdezu 2016-11-04 22:25:28 +08:00
想知道 sklearn 对 tensorflow 有什么优势? 小米加步枪对大炮
|
 |
9
RangerWolf 2016-11-11 10:06:18 +08:00
@songdezu 普通问题用 sklearn 就很好了~ 如果你普通的机器学习算法搞不定再考虑深度学习。
深度学习对数据量以及计算能力都有不低的要求 |
 |
10
lll9p 2016-11-11 10:22:22 +08:00 via Android
@songdezu sklearn 打包了常用的机器学习算法,适合快速实验。。 TensorFlow 是基于符号运算的库,基本上为深度学习打造。。
|
 |
11
simapple 2016-11-11 10:54:06 +08:00
又是软文广告贴
|
 |
12
ivincent 2017-04-20 08:09:25 +08:00
翻译转贴丢失了很多信息,英文原帖包含更多重要信息,例如一步步建立 Jupyter Notebook ,如何生成数据可视化等等,如果可能最好去直接看英文吧 https://jmetzen.github.io/2015-01-29/ml_advice.html
|