
这是一个创建于 1462 天前的主题,其中的信息可能已经有所发展或是发生改变。
这阵子在做 Tesseract-OCR 的字体训练,其中遇到了几个问题,使我很烦恼,特意来求教各大佬
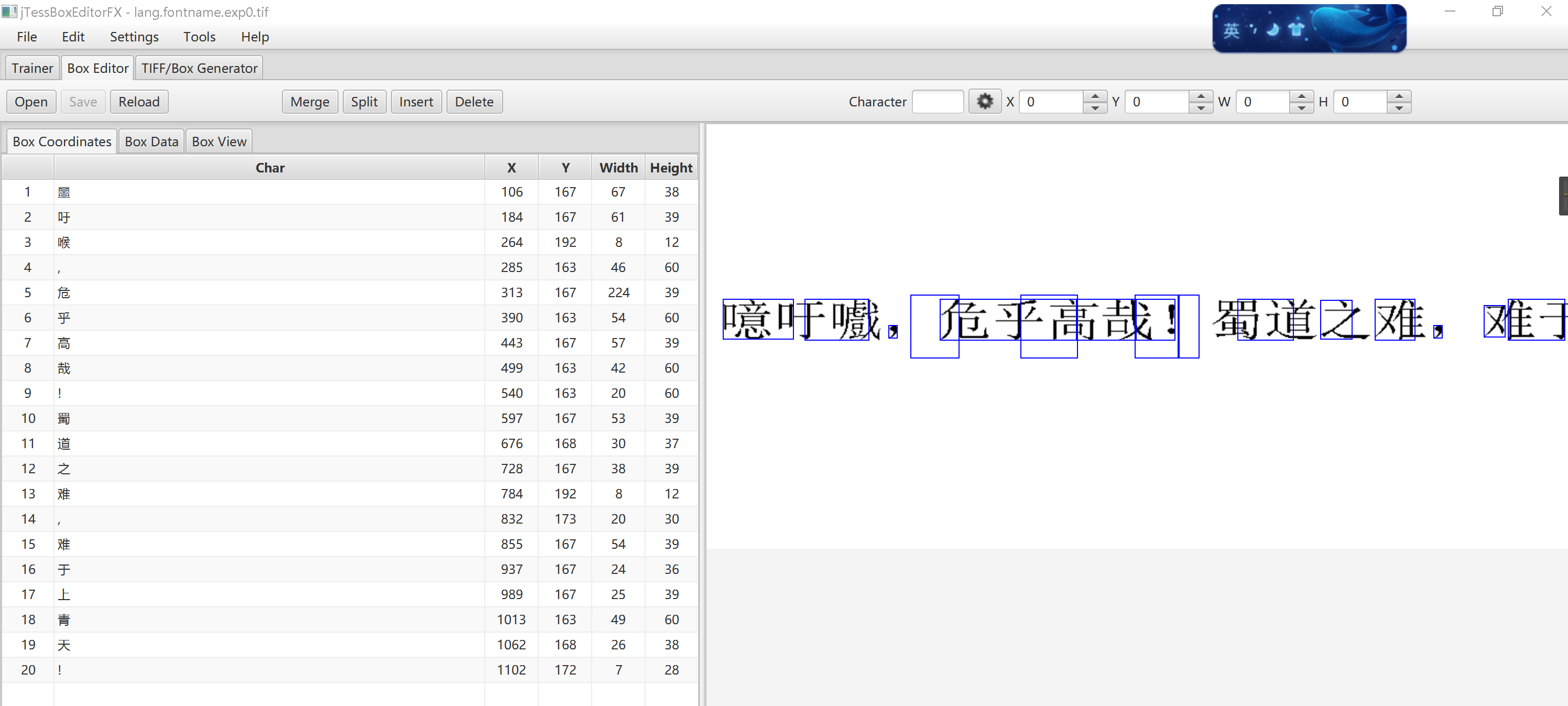
1 、 在将图像生成对应的 .box 文件后,使用 jTessBoxEditorFx 软件进行校正时,发现字体虽然大部分都能识别出来,但是每个字的位置却出现了很严重的偏差,如下图,需要逐个字体进行校正位置坐标才行(如下图一),不知道这是什么原因引起的。(每个字都需要进行位置校正,工程量太大了)
2 、 字体训练后,单独使用我训练过的字体包来识别图像,只能识别出那些我有训练过的文字,如果图像出现了我没训练过的文字,这些文字就会胡乱显示为我训练过的文字,如下图(这问题我还能理解)
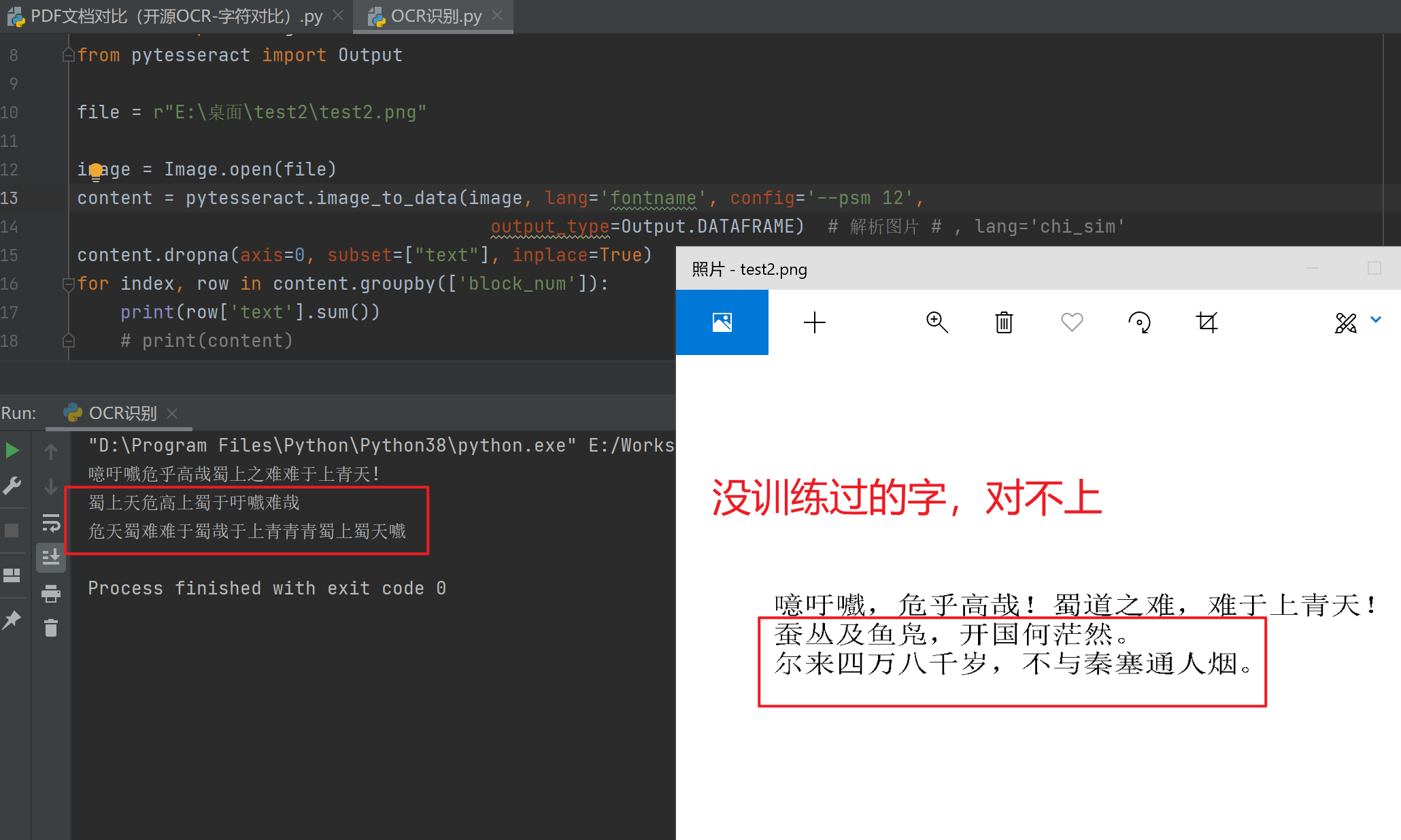
3 、如果在识别时,设置语言包 lang 的参数为 我训练过的字体包 + 通用中文简体包 chi_sim,识别出来的文字则和单独使用通用中文简体包 chi_sim效果一致,也就是说我训练的字完全不起作用。如下图
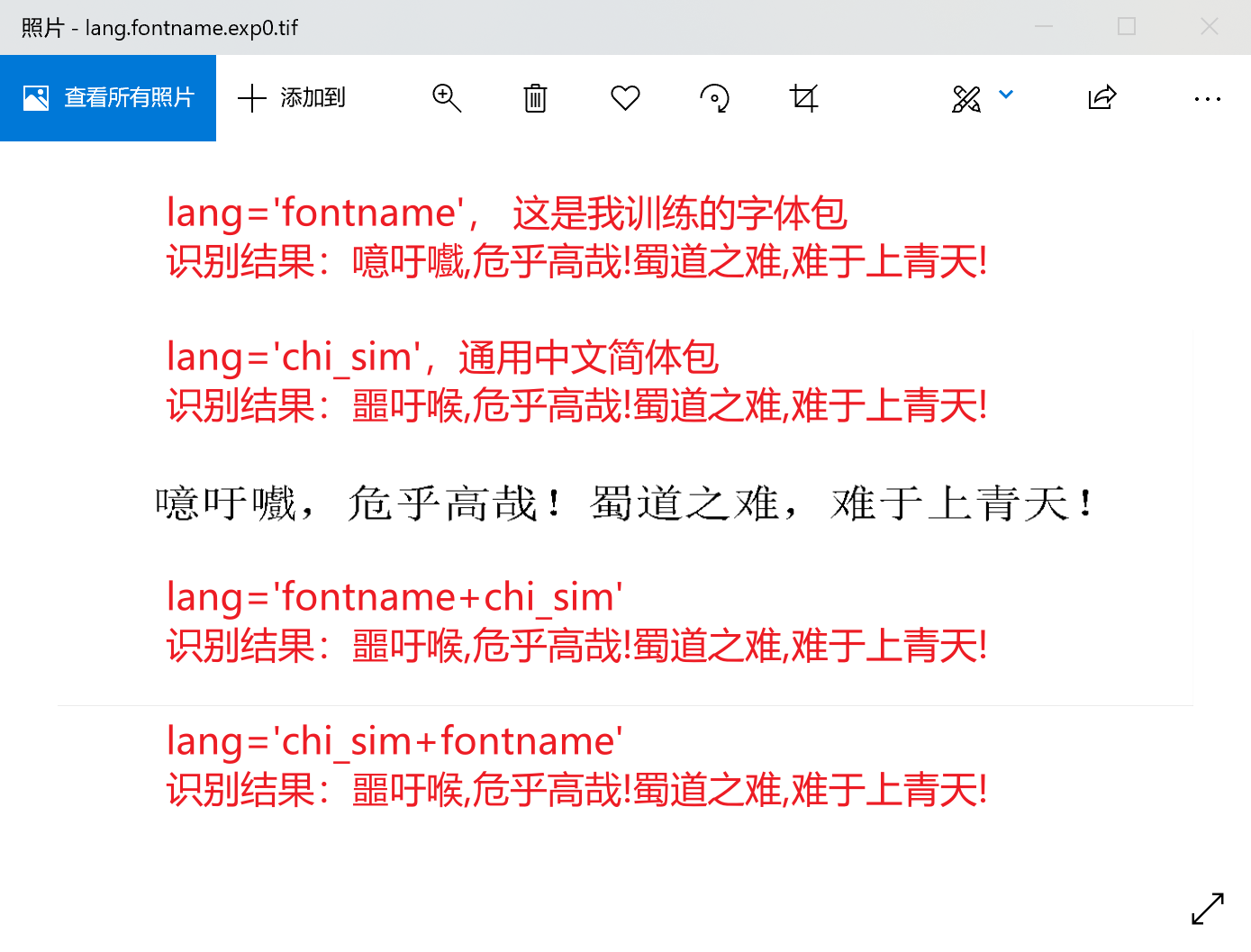
我预期的结果:我训练的字体包和官方的字体包可以在一起使用(毕竟自己不可能每个字都训练到,这还是得靠官方支持)。各位大佬何以教我
 |
1
95276 2020-12-10 17:23:22 +08:00
感觉应该要把你训练的和官方的合并一下 或者在官方的基础上训练.
|
 |
2
zhuangzhuang1988 2020-12-10 17:42:58 +08:00
放弃吧 这货 巨费时间
而且 新的 Tesseract 也不是基于具体的字训练的 记得是基于行训练的 |
 |
3
sadfQED2 2020-12-10 19:20:30 +08:00 via Android
我曾经花过半个月时间整理训练集,然后提交训练,最后发现结果很一般。
然后,我花了三天时间自己用 tensorflow 写了一个文字识别,然后一跑训练集,比它这玩意效果还好点 另外,你想要的应该是合并训练集 |